riskratioprog

Contents
riskratioprog subroutine maximizes ratio of risk functions with linear constraints. For instance, this subroutine can maximize a "Sharpe-like" ratio of mean access return (linear function) and CVaR deviation.
Mathematical Problem Statement
The subroutine solver the following optimization problem:

subject to

where
A, and Aeq are matrices;
d, and x are column vectors;
b, beq, lb, and ub are column vectors or scalars.
risk1 and risk2 are PSG risk functions or PSG deterministic functions (see List of risk functions for riskratioprog).
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b)
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b, Aeq, beq)
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b, Aeq, beq, lb, ub)
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b, Aeq, beq, lb, ub, x0)
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b, Aeq, beq, lb, ub, x0, options)
[xout, fval] = riskratioprog (…)
[xout, fval, status] = riskratioprog (…)
[xout, fval, status, output] = riskratioprog (…)
Remarks
Omitted parameters should be substituted by square brackets “[]”.
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b) returns a vector x that maximizes ![]() subject to
subject to ![]() . The PSG functions risk1 and risk2 are specified by w1, H1, c1, p1, w2, H2, c2, and p2.
. The PSG functions risk1 and risk2 are specified by w1, H1, c1, p1, w2, H2, c2, and p2.
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b, Aeq, beq) solves the problem additionally satisfying the equality constraints ![]() .
.
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b, Aeq, beq, lb, ub) solves the problem with bounds on decision variable x, so that the solution is in the range ![]() .
.
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b, Aeq, beq, lb, ub, x0) sets the starting point x0 (see Initial Point).
xout = riskratioprog (risk1,risk2, w1, H1, c1, p1, w2, H2, c2, p2, d, A, b, Aeq, beq, lb, ub, x0, options) maximizes with the optimization options specified in the structure options.
[xout, fval] = riskratioprog (…) returns the value of the objective function on point x: ![]() . The PSG functions risk1, and risk2 are specified by w1, H1, c1, p1, w2, H2, c2, and p2.
. The PSG functions risk1, and risk2 are specified by w1, H1, c1, p1, w2, H2, c2, and p2.
[xout, fval, status] = riskratioprog (…) returns a problem status ={ optimal | feasible | unbounded | infeasible } describing the exit status of riskratioprog.
[xout, fval, status, output] = riskratioprog (…) returns a structure output containing information about the optimization with riskratioprog.
risk1 |
name of PSG function (see List of risk functions for riskratioprog); |
risk2 |
name of PSG function (see List of risk functions for riskratioprog); |
w1 |
parameter (real) of the PSG function risk1. If parameter is not present, then substitute parameter by square brackets “[]” ); |
w2 |
parameter (real) of the PSG function risk2. If parameter is not present, then substitute parameter by square brackets “[]” ); |
H1 |
matrix for PSG function risk1; |
H2 |
matrix for PSG function risk2 |
c1 |
vector of benchmark for PSG function risk1. If the benchmark is not used, then substitute it by square brackets “[]”; |
c2 |
vector of benchmark for PSG function risk2. If the benchmark is not used, then substitute it by square brackets “[]”; |
p1 |
vector of probabilities for PSG function risk1. If all probabilities are equal, you can substitute p1 by square brackets “[]”); |
p2 |
vector of probabilities for PSG function risk2. If all probabilities are equal, you can substitute p2 by square brackets “[]”); |
d |
column vectors for linear component of objective; |
A |
matrices for linear inequality constraint; |
b |
vectors or scalars for linear inequality constraint; |
Aeq |
matrices for linear equality constraint; |
beq |
vectors for linear equality constraint; |
lb |
vectors of lower bounds; |
ub |
vectors of upper bounds; |
x0 |
initial point for x (see Initial Point); |
options |
structure that contains optimization options (see Options); |
Strucure output contains information about the optimization. The fields of the structure are:
xout |
optimal point; |
fval |
optimal value of objective function |
frval1 |
optimal values of PSG functions risk1; |
frval2 |
optimal values of PSG functions defined in risk constraint risk2; |
fdval |
optimal values of linear component of objective; |
fAval |
optimal values of left hand sides of linear inequality constraints; |
rAval |
residual of linear inequality constraints; |
fAeqval |
optimal values of left hand sides of linear equality constraints; |
rAeqval |
residual of linear equality constraints; |
data_loading_time |
data loading time; |
preprocessing_time |
preprocessing time; |
solving_time |
solving time. |
Structure options contains optimization options used by riskratioprog. The fields of the structure are:
Solver |
choose optimization PSG solvers from a list: VAN, CAR, BULDOZER, TANK (for more details see Optimization Solvers); |
Precision |
number of digits that solver tries to obtain in objective and constraints; |
Time_Limit |
time in seconds restricting the duration of the optimization process; |
Stages |
number of stages of the optimization process (this parameter should be specified for VaR, Probability, and Cardinality groups of functions). |
Linearization |
controls internal representation of risk function, which can speed up the optimization process (used with CAR and TANK solvers). 'On' or 'Off' (default) (see Linearizing); |
Path_to_Export_to_Text |
string with path to the folder for storing problem in General (Text) Format of PSG). If Path_to_Export_to_Text=‘’ (default) than the problem is not exported in General (Text) Format of PSG; |
Path_to_Export_to_MAT |
string with path to the folder for storing problem as mat-file. If Path_to_Export_to_MAT=‘’ (default) than the problem is not exported as mat-file. This option is intended for converting the problem to the PSG MATLAB Data Structure; |
Display |
key specifying if messages that may appear when you run this subroutine should be suppressed (Display = 'Off') or not (by the default: Display ='On') (see PSG Messages); |
Warnings |
key specifying if warnings that may appear when you run this subroutine should be suppressed (Warnings = 'On') or not (by the default: Warnings ='Off'); (see PSG Messages) |
Types |
specifies the variables types of a problem. If Types is defined as column-vector, it should include as many components as number of variables Problem includes. The components of column-vector can possess the values "0" - for variables of type real, or 1- for variables of type boolean, or 2 - for variables of type integer. If Types is defined as one number (0, or 1, or 2) than all variables types real, or boolean, or integer respectively. |
Find ![]() maximizing
maximizing
![]()
subject to
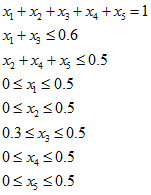
First, consider parameters, specifying the PSG function risk1 from mathematical problem statement of riskratioprog subroutine:
risk1='pm_pen';
w1=0.01;
Matrix:

benchmark vector is

p1=[];
Next, consider parameters, specifying the risk function risk2.
Since Average_Gain = - Average_Loss, then
risk2 = 'avg';
H2=H1;
c2=c1;
p2=[];
Run the following example from ./Aorda/PSG/MATLAB/Examples/Problems/Example_riskratioprog.m or type the next PSG problem in MATLAB:
Define input data:
H1 = [0.11 0.04 -0.12 0.01 -0.05; ...
-0.01 -0.1 0.03 0.21 0.01; ...
0.05 0.2 0.07 -0.03 -0.12; ...
-0.1 0.14 0.04 -0.1 0.09; ...
0.08 -0.02 -0.2 0.07 -0.01; ...
0.17 0.3 -0.12 -0.02 0.08
];
c1 = [0.06; -0.1; 0.12; 0.01; -0.06; 0.11];
A = [1 0 1 0 0; 0 1 0 1 1];
b = [0.6; 0.5];
Aeq = [1.0 1.0 1.0 1.0 1.0];
beq = 1.0;
lb = [0.0; 0.0; 0.3; 0.0; 0.0];
ub = [0.5; 0.5; 0.5; 0.5; 0.5];
Next, run the subroutine :
[x, fval, status, output] = riskratioprog('pm_pen', 'avg', 0.01, H1, c1, [], [], H1, c1, [], [], A, b, Aeq, beq, lb, ub)
You get the following output:
Optimal point:
xout =
0.2000
0.5000
0.3000
0
0
Objective value on the optimal point:
fval =
2.5000
Status of the solved optimization problem:
status =
optimal
Full report for solution of the optimization problem:
output =
xout: [5x1 double]
fval: 2.5000
fdval: []
frval1: 0.0073
frval2: -0.0183
fAval: [2x1 double]
rAval: -0.1000
fAeqval: 1
rAeqval: 0
data_loading_time: 0
preprocessing_time: 0
solving_time: 0
Case Studies with riskratioprog
| • | Omega Portfolio Rebalancing. |
riskprog, riskparam, riskconstrprog, riskconstrparam
List of risk functions for riskratioprog
Subroutine riskconstrprog works only with PSG functions described in this section.
Remarks
riskratioprog can be used when:
| • | there should exists at least one feasible point on which numerator in the objective must be strongly positive; |
| • | denominator in the objective must be non-negative on all feasible points that satisfy additional inequality "numerator >=1". |
Full Name |
Brief Name |
Short Description |
|---|---|---|
avg |
Average Loss obtained by averaging Linear Loss scenarios, i.e., it is a linear function with coefficients obtained by averaging coefficients of Linear Loss scenarios. |
|
avg_g |
Average Gain obtained by averaging -(Linear Loss ) scenarios, i.e., it is a linear function with coefficients obtained by averaging coefficients of -(Linear Loss) scenarios. |
|
cdar_dev |
For every time moment, j=1,...J , portfolio drawdown = d(j) = maxn ((uncompounded cumulative portfolio return at time moment n ) - (uncompounded cumulative portfolio return at time moment j )). CDaR = CVaR Component Positive of vector (d(1), ..., d(J)) = average of the largest (1-α)% components of the vector (d(1), ..., d(J)), where 0≤α≤1 . |
|
cdar_dev_g |
For every time moment, j=1,...J , portfolio -drawdown = -d(j) = maxn (-(uncompounded cumulative portfolio return at time moment n ) + (uncompounded cumulative portfolio return at time moment j )). CDaR for Gain = CVaR Component Positive of vector (-d(1), ...,- d(J)) = average of the largest (1-α)% components of the vector (-d(1), ..., -d(J)), where 0≤α≤1 . |
|
cvar_comp_neg |
Average of the largest (1-α)% of components of a -( vector), where 0≤α≤1 |
|
cvar_comp_pos |
Average of the largest (1-α)% of components of a vector, where 0≤α≤1 |
|
cvar_dev |
Conditional Value-at-Risk for (Linear Loss) - (Average over Linear Loss scenarios) , i.e., the average of largest (1-α)% of (Linear Loss) - (Average over Linear Loss scenarios) scenarios. |
|
cvar_dev_g |
Conditional Value-at-Risk for -(Linear Loss ) + (Average over scenarios Linear Loss) , i.e., the average of largest (1-α)% of - (Linear Loss) + (Average over scenarios Linear Loss) scenarios. |
|
cvar_risk |
Conditional Value-at-Risk for Linear Loss scenarios (also called Expected Shortfall and Tail VaR), i.e., the average of largest (1-α)% of Losses. |
|
cvar_risk_g |
Conditional Value-at-Risk for -(Linear Loss ) scenarios (also called Expected Shortfall and Tail VaR), i.e., the average of largest (1-α)% of -(Losses). |
|
drawdown_dev_avg |
For every time moment, j=1,...J , portfolio drawdown = d(j) = maxn ((uncompounded cumulative portfolio return at time moment n ) - (uncompounded cumulative portfolio return at time moment j )). Drawdown Deviation = average of components of the vector (d(1), ..., d(J)) . |
|
drawdown_dev_avg_g |
For every time moment, j=1,...J , portfolio -(drawdown) = -d(j) = maxn (-(uncompounded cumulative portfolio return at time moment n ) + (uncompounded cumulative portfolio return at time moment j )). Drawdown Average for Gain = average of components of the vector (-d(1), ...,- d(J)). |
|
drawdown_dev_max |
For every time moment, j=1,...J , portfolio drawdown = d(j) = maxn ((uncompounded cumulative portfolio return at time moment n ) - (uncompounded cumulative portfolio return at time moment j )). Drawdown Maximum = Maximum Component Positive of vector (d(1), ..., d(J)) = largest component of the vector (d(1), ..., d(J)). |
|
drawdown_dev_max_g |
For every time moment, j=1,...J , portfolio -drawdown = -d(j) = maxn (-(uncompounded cumulative portfolio return at time moment n ) + (uncompounded cumulative portfolio return at time moment j )). Drawdown Maximum for Gain = Maximum Component Positive of vector (-d(1), ...,- d(J)) = largest component of the vector (-d(1), ..., -d(J)). |
|
linear |
Linear function with many variables |
|
max_comp_neg |
Maximal (largest) component of -(vector) |
|
max_comp_pos |
Maximal (largest) component of a vector |
|
max_dev |
Maximum of ((Linear Loss ) - (Average over Linear Loss scenarios)) scenarios. |
|
max_dev_g |
Maximum of (-(Linear Loss ) + (Average over Linear Loss scenarios)) scenarios.. |
|
max_risk |
Maximum of Linear Loss scenarios. |
|
max_risk_g |
Maximum of -(Linear Loss ) scenarios. |
|
meanabs_dev |
Mean Absolute Deviation for Linear Loss scenarios. |
|
meanabs_pen |
Mean Absolute for Linear Loss scenarios function. Calculated by averaging over scenarios the absolute values of losses . |
|
meanabs_risk |
Mean Absolute for Linear Loss scenarios. (Mean Absolute) =Average Loss + Mean Absolute Deviation. |
|
meanabs_risk_g |
Mean Absolute for Gain for Linear Loss scenarios. (Mean Absolute for Gain) = -Average Loss + Mean Absolute Deviation. |
|
pm_dev |
Expected access of ( (Loss ) - (Average Loss )) over some fixed threshold. |
|
pm_dev_g |
Expected access of (- (Loss ) + (Average Loss )) over some fixed threshold. |
|
pm_pen |
Expected access of ( (Loss ) - (Average Loss )) over some fixed threshold. |
|
pm_pen_g |
Expected access of -( Loss ) over some fixed threshold. |
|
polynom_abs |
Sum of absolute values of components of a vector, i.e., L1 norm of a vector. |
|
st_dev |
Standard Deviation of Linear Loss scenarios calculated with Matrix of Scenarios. |
|
st_pen |
Root Squared Error of Linear Loss scenarios calculated with Matrix of Scenarios or Expected Matrix of Products. By definition, it is an average of squared loss scenarios. |
|
st_risk |
(Standard Deviation of Linear Loss scenarios)+(Average of Linear Loss scenarios). It is calculated with Matrix of Scenarios. |
|
st_risk_g |
(Standard Deviation of Linear Loss scenarios)-(Average of Linear Loss scenarios). It is calculated with Matrix of Scenarios. |
|
var_comp_neg |
α*I -th value in the ordered ascending sequence of components of a -(I-dimensional vector), where 0≤α≤1; e.g., α=0.8, I=100, we order components of the -(vector) and take the element number α*I = 80 |
|
var_comp_pos |
Maximal (largest) component of a vector . |
|
var_dev |
Value-at-Risk for (Linear Loss ) - (Average over Linear Loss scenarios) , i.e., α% percentile of (Linear Loss) - (Average over Linear Loss scenarios) scenarios. |
|
var_dev_g |
Value-at-Risk for -(Linear Loss ) + (Average over Linear Loss scenarios) , i.e., α% percentile of -(Linear Loss) + (Average over Linear Loss scenarios) scenarios. |
|
var_risk |
Value-at-Risk for Linear Loss scenarios, i.e., α% percentile of Linear Loss scenarios. |
|
var_risk_g |
Value-at-Risk for -(Linear Loss ) scenarios, i.e., α% percentile of -(Linear Loss) scenarios. |